
As a Technical Principal, I had the opportunity to work with one of the largest US airlines to build their consumer facing mobile application. My role was to ensure that the application was technically sound and remove any roadblocks for the team. During my stint on the project, one of our challenges was to help the entire team adopt continuous delivery. We had a team of approximately 80 people distributed over three locations. This post chronicles our journey to continuous delivery, the challenges along the way, and how we overcame them.
How we overcame challenges on the road to Continuous Delivery
1. Creating a robust build infrastructure
One of the most critical success factors for any large distributed team is developer productivity. And having a robust and stable build infrastructure is key. The build infrastructure needs of a mobile project are very unique and working with emulators/simulators was difficult compared to working with web browsers.
We used to run simulations of tests on different environments, the primary among them being Mac OS (for the iOS app). At first, we provisioned these machines manually. This process not only took over two days but also left us a lot of configuration drift in the build agents. We ended up with poor utilization of our hardware, long waiting time for build (as long as 1.5 days) and significant loss of productivity in managing infrastructure.
To mitigate this, we decided to completely automate the provisioning of our build agents using Ansible. We also created a pre-baked machine image by running our automated provisioning scripts over a vanilla Mac OS installation. We called this our “golden image”. At any time, if a build agent failed due to accidental configuration drift, we just restored the ‘golden image’ on that agent. We also introduced the concept of ‘homogeneous’ build agents. This enabled all build agents to run all build types (Android/iOS).
All these helped reduce our machine provisioning time drastically - from two days to less than 30 minutes.
2. Making test failures more visible
When we started, we had inherited a monolithic application. Over time, with more and more functionality getting added to the application, our functional regression suite became extremely difficult to work with. There was a single pipeline per platform (Android/iOS), and it always used to be red. It was extremely tedious to figure out which part of the application was broken. Our goal here became to make the test failures more visible, and help identify which parts of the application need our attention. To this end, we broke down the single regression test suite pipeline into multiple functional pipelines. This also helped us maintain our regression test suite in a green state.
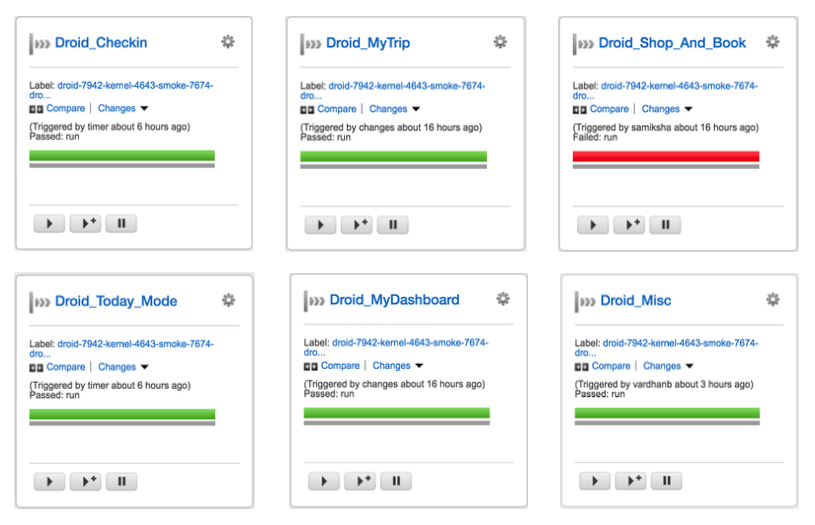
3. Ensuring that every commit leaves the pipeline in a ‘releasable’ state
Initially, the team were doing feature branches, which caused a lot of strain. Every time we merged a feature branch, it took a lot of effort and would halt everyone for a day or two before things went back to schedule. What made it more tricky, was that we used to run CI only on our master and not on the feature branches. A branch where the code was getting pushed almost daily generally lived three to four months without continuous integration. People were doing their due diligence to make sure they’d merge master back into the feature branch to keep the code up to date, but that was never enough. We had (at one point) eight feature teams in multiple locations; it was inevitable that people would cross paths.
Another deeper problem caused by long-lived feature branches was that our team started becoming hesitant to do any re-factoring. When you know that the merge is going to be very difficult, people used to shy away from re-factoring even knowing that things are in bad shape. That meant that a huge amount of technical debt started accumulating.
We started focussing on ensuring that every commit left the pipeline in a releasable state. We approached this goal in two ways, by:
- building adequate tests into our CD Pipeline and
- developing code keeping in mind CI/CD practices.
Here’s a quick view of what our CD pipeline looked like by the end.
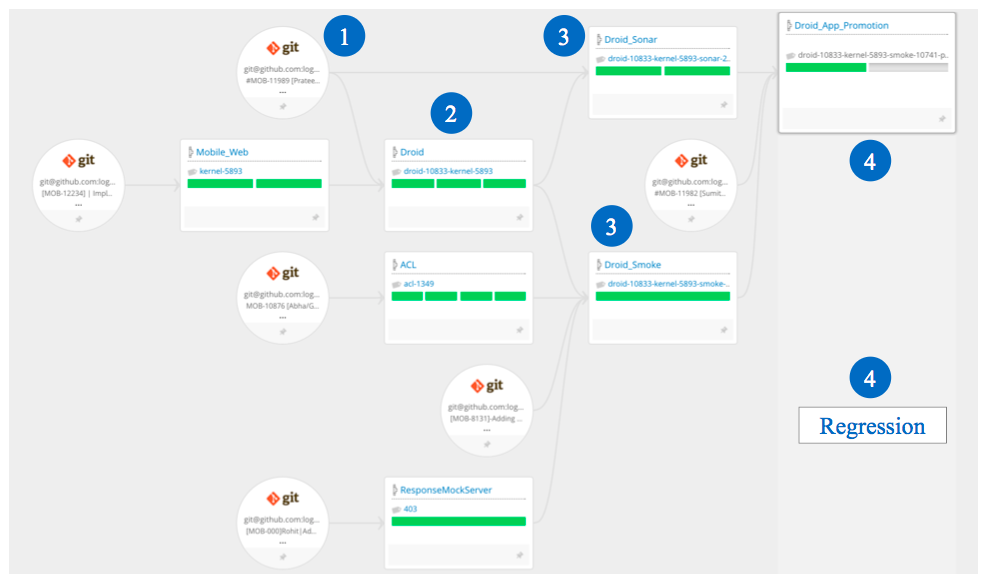
We had a combination of unit tests, integration tests, smoke tests, and regression tests (visual and functional) to make sure that each commit was ready to be deployed.
Along with this, we also educated our team to
- choose feature toggles over feature branches,
- commit regularly to master and
- rely on continuous integration tests.
After adopting these practices, some of these challenges just went away. Now, we see that the level of confidence that the developers have when pushing any piece of code is very high.
4. Introducing quality as part of the deployment pipeline
In most typical setups, code quality is monitored outside of the deployment pipeline. One of the steps we took to ensure continuous delivery was making sure that code quality is part of the build pipeline. Rather than having it to be a dashboard that just worked independently of our pipeline, we integrated our build pipeline with the SonarQube Server. This allowed us to be able to run quality checks on every commit as part of the build process.
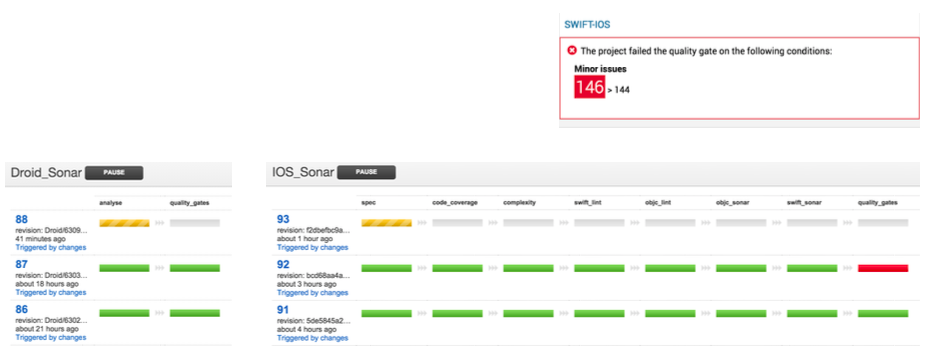
Apart from this, we also added strong quality gates. So if there was a failure in SonarQube, we failed the particular build as well. This helped bring the focus of the team on quality of the code. If the code quality failed at any stage, it meant that the build was a failure, and the team sought to fix that with the same urgency as any other failure.
5. Taking advantage of a good continuous delivery tool
Customization and the ability to orchestrate
Before we could start leveraging our CD tool, we had to make sure that we were able to automate and continuously integrate. A CD tool can only take you so far. That said, we found the pipelines in GoCD really powerful as a first class concept. Once we got the concepts of pipelines, stages, jobs, etc. we used GoCD to our advantage to build custom workflows and were able to define what CI/CD looked like for us.
Traceability
Picking a tool that gives advanced traceability can save you a lot of time and agony. Recently, there was an issue that required us to make a hotfix. Due to an error, the wrong git material was picked for the release pipeline. This resulted in the wrong artifact being produced and so there were random failures all over. It’s not uncommon for these types of incidents to happen in projects, and without a tool that offers traceability, it would take a lot of effort to troubleshoot.
The impact of these changes
Honestly, the best thing after adopting continuous delivery is that we move much faster than before and with confidence.
Some measurable changes that we saw were:
- The machine provisioning time reduced from two days to less than 30 minutes.
- The build waiting time reduced from 6 hours to less than 10 seconds.
What’s impactful is that less waiting means developers can focus without wasteful interruption. We have a big boost on team productivity. A positive change that we cannot really quantify was the effect on our culture! Our team became proactive about re-factoring and tackling tech-debt. Continuous integration and automation became the new normal.
Beyond Continuous Delivery
After these improvements, we wanted to go a bit further and find ways to improve our delivery process. We felt the need to have continuous monitoring or continuous feedback to keep understanding what needs to be fixed in our deployment cycle. This is a place that I felt that tools like GoCD need to evolve. The idea was to get some reporting and actionable insights into our deployment cycle so we as a team can make changes as we go. Eventually, we built a custom analytics module suited for our application that we could draw insights from.
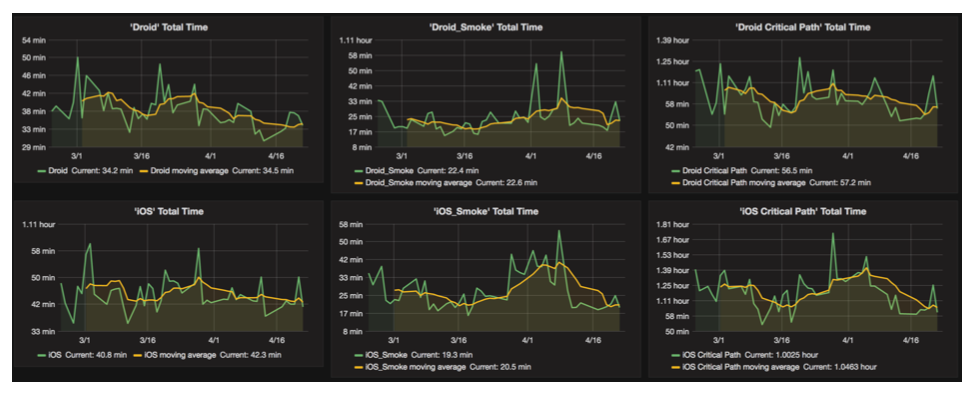
At its core, continuous delivery is a journey. In my experience, it was adopting a balance of all of these practices that helped us get closer to our goals for deployment. I don’t think we could have achieved the same measure of success with the same velocity had we only chosen to focus on one or two practices. From where we started, the benefits we experienced using CD practices have been immeasurable. It can be a challenge in the beginning, but if you stick by it, it hugely improves not just the quality of code that gets delivered but the quality of the team as well.
Sanchit Bahal is a Lead Technical Consultant with Thoughtworks and has over 14 years of experience in building complex enterprise applications. He loves using devops practices and principles to build high performing delivery teams.