
This is the second post in the series - Continuous Delivery for Microservices. In my previous post, I gave an overview of five considerations for building CD pipelines on a microservices architecture. In this post, we’ll get deeper into test strategy.
Test Strategy
A microservices architecture involves many moving parts with different guarantees and failure modes. Testing and verification of these systems are significantly more nuanced and complex than testing a traditional monolithic application. An effective test strategy needs to account for both testing individual services in isolation and the verification of overall system behavior. You can broadly break testing down into two categories: pre-production testing and monitoring and testing in production.
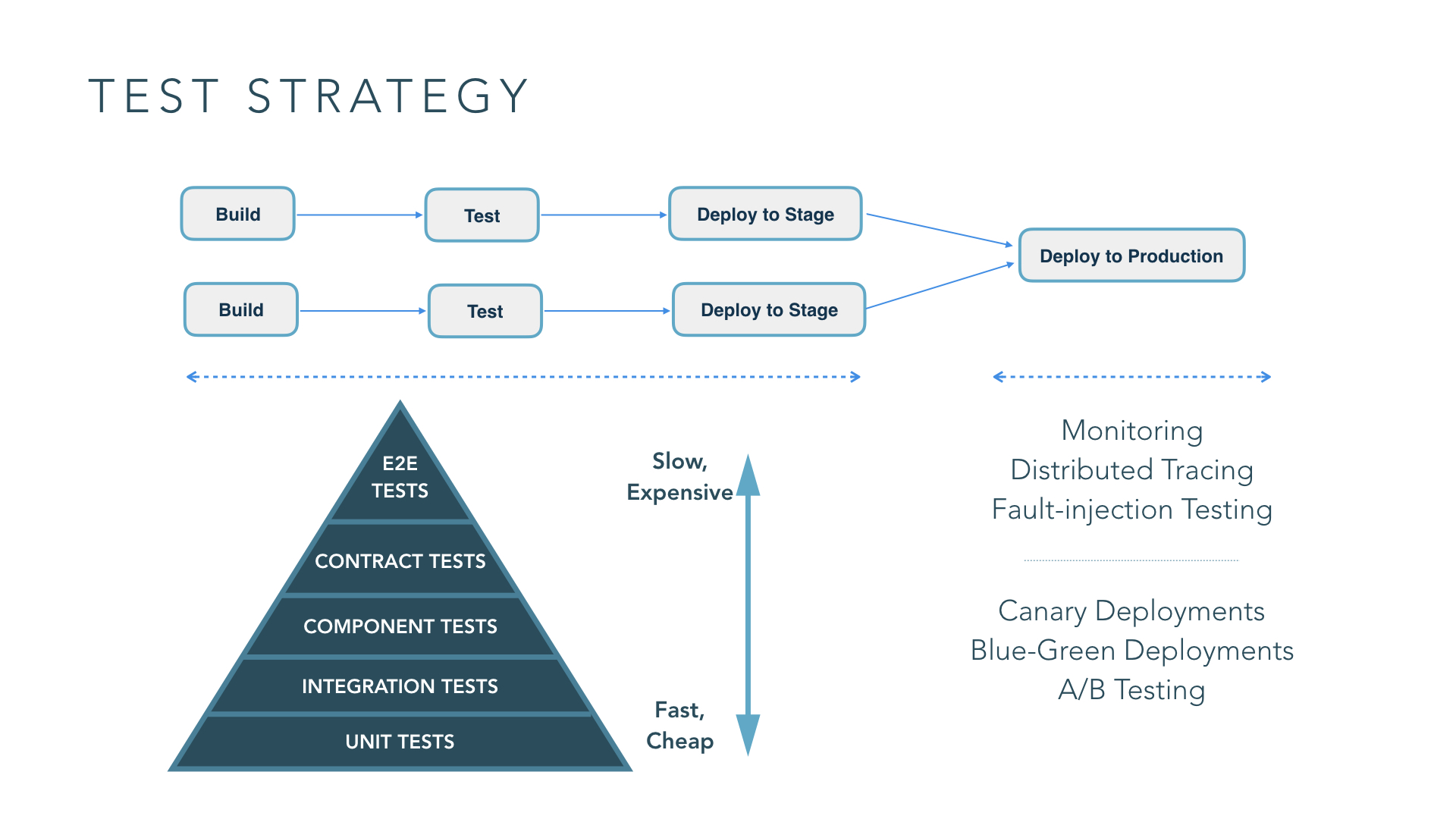
Pre-production testing of services
Here’s a simple example where you have build pipelines for multiple services and you’re testing a service in isolation. In this case, the traditional test pyramid helps to maintain a balance between the different types of tests.
In a typical test pyramid, you have:
Unit tests
Tests that cover the smallest piece of testable functionality in your software.
Integration tests
Integration tests, in this context, deal with testing integrations and interface defects for components within your service; these are more granular tests.
Component tests
When you look at component tests for microservices, a component is a service that exposes certain functionalities. Therefore, component tests for microservice can just be acceptance tests for services and your tests need to validate whether the service provides the functionality that it promises to.
Contract tests
Another category of tests that’s very applicable to microservices are contract tests. They test the contracts of APIs of your services to see if the API is valid or if the microservice honors its API. A cool variation of these contract tests is consumer driven contract tests. These tests are written by consumer services of an API; the consumers codify this contract in a suite of tests that get run on every change to the API. That way, if a change to the API breaks a contract that one of its consumers expect, this breaking change is caught early in the CD pipeline.
End-to-end tests
The test suites we discussed earlier are applicable to testing individual services. End-to-end tests, however, are more coarse-grained and try to test the functionality of an overall system. Depending on the deployment architecture you’re going for, if you are deploying all of your services in a pre-production environment in an aggregate manner, you can run end-to-end tests there. Since end-to-end tests are usually brittle and take a long time to run, you’ll usually want to restrict the number of these tests to as few as possible. If you have microservices that are completely independent and don’t get deployed to a pre-production test environment, then consider approaches that test in production.
Monitoring and testing in production
This traditional style of testing has its limitations. There are categories of errors that you can’t really simulate in test environments. Examples of these sorts of issues include issues caused by eventual consistency in a highly distributed system, and hardware and network failures causing parts of the system to fail. You have to supplement traditional testing techniques with techniques that allow you to profile and monitor systems in production effectively, and the ability to take remedial action in production when things do go wrong. In this post, I will focus on testing in production, and cover remediation strategy in a later part of this series.
There is a category of testing in production called fault-injection, which is introducing errors in a controlled manner in production to see if your system can hold up to those errors.
A variation of in-production testing are some specific deployment strategies that are popular in these environments:
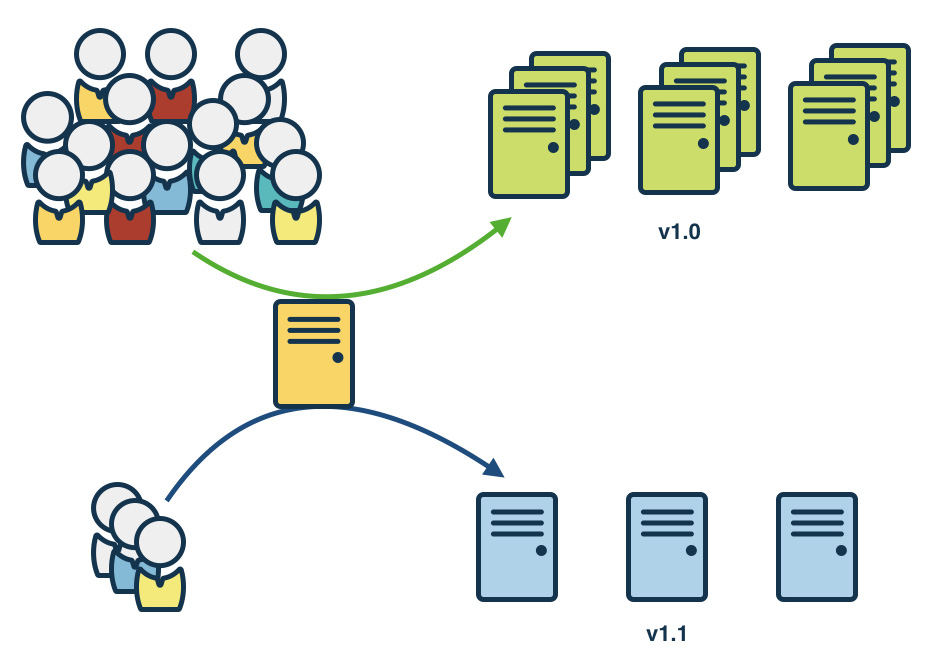
Canary deployment
Canary deployment is where you take a new release and release it to a certain subsection of your production infrastructure, see how well that goes, and keep increasing the footprint of the new service until the time you completely roll it out. If you face issues, you can start rolling back the new version of your service.
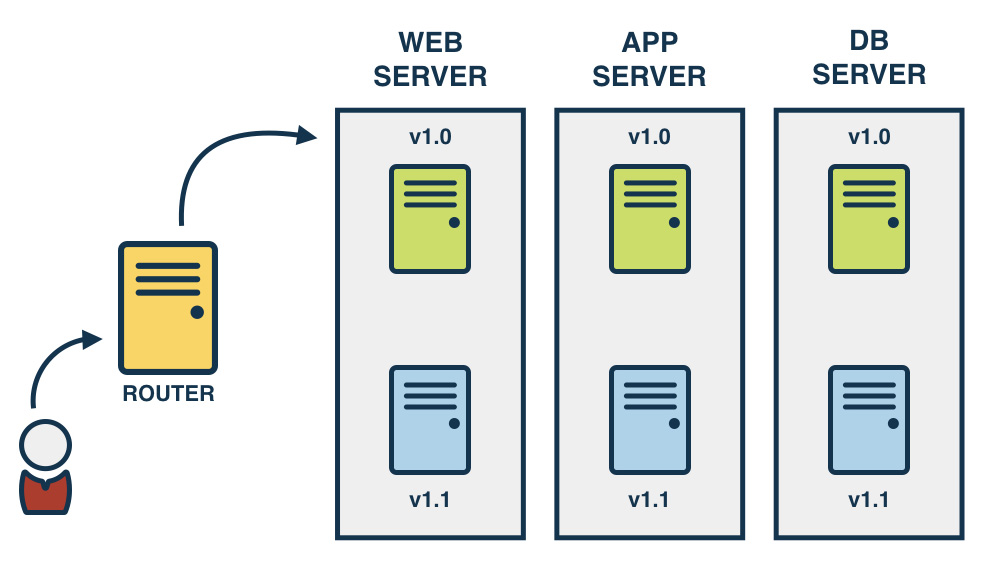
Blue-Green deployment
Blue-green deployments are similar, where you have a new footprint of your new service, and then you do some testing and route some traffic through it. If everything is fine, you switch over all of your traffic to the new instance of services, otherwise, you keep the old footprint going.
Multivariate testing
Another interesting variation of this kind of testing is multivariate testing, where you’re not really testing your new service against defects, instead, you are A/B testing new release features behind A/B testing toggles. The purpose of this type of testing is to see how well these features are received. You can decide roll it out to your entire set of users or make fixes where necessary.
Summary
This is part 2 of our Continuous Delivery for Microservices blog series. We have talked in depth about testing strategies for microservices, which include how to apply traditional testing pyramids to pre-production testing for microservices and also new techniques for production monitoring and testing. In my next post, we will talk about the second consideration: CI practices for microservices systems.